





Advertising
12 Apple ad campaigns spanning over 40 years — The hits and misses
8 min read
By Mario Neto

You might ask yourself "Why should I do Facebook A/B testing?". An inevitable fact of life is no matter how much you improve your ROAS, you’re guaranteed to run into posts on Facebook where others claim to have much better results than you. This happened to me so
You might ask yourself "Why should I do Facebook A/B testing?". An inevitable fact of life is no matter how much you improve your ROAS, you’re guaranteed to run into posts on Facebook where others claim to have much better results than you.
This happened to me so many times and my reaction has always been the same—"I got to try this." Sometimes they worked in a way, although I can’t say exactly why. Once a colleague of mine asked me how a recent change I did worked. The honest answer was—I had no idea.
Whenever someone mentioned the best way to scale Facebook ad campaigns was something like doubling the budget three times a day, I would do it. Then I’d get a few expensive days, my account CPA would skyrocket, and I’d just drop the idea and move on to the next one. Now I understand this approach was chaotic and the results were random.
Before jumping into the Framework, let me explain a few details of Facebook ads A/B testing.
Facebook A/B testing is a method of comparing two versions of a Facebook ad or campaign to see which one performs better.
It is done by randomly dividing your target audience into two groups and showing each group a different version of the ad or campaign. After a certain period of time, you can compare the results of the two groups to see which version performed better.
Facebook A/B testing can be used to test a variety of different variables, such as:
To create an A/B test on Facebook, you can use the Ads Manager tool or the Experiments tool.
I haven't had the best experiences using the Facebook built in tool. If you have only a few variations to test, it's alright to use it, but as the complexity of your tests increase, the harder will be to set them up directly on Facebook.
To create a Facebook A/B test inside the Ads Manager there are a few steps.
First you'll log in to the Ads Manager and create a new campaign. On the campaign settings, there will be an option to "Create A/B Test"
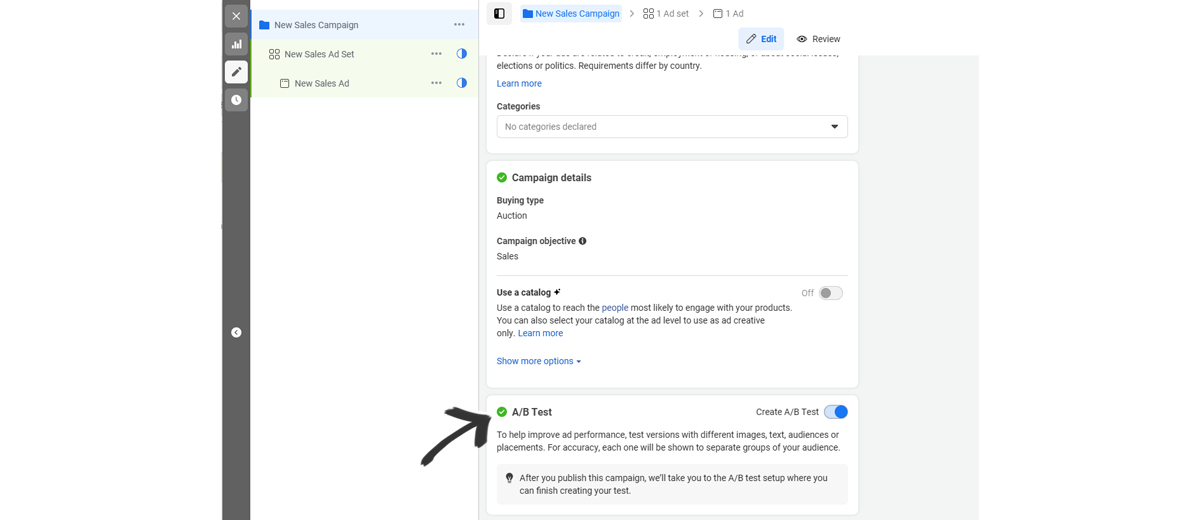
You can proceed with the settings for your campaign, then ad set and ad level. At the end you'll be taken to the "Experiments" page and you can set the test from there.
Another option while creating the campaign is to duplicate the Ad set.
You will click on the three dots next to the Ad set and then "Duplicate".
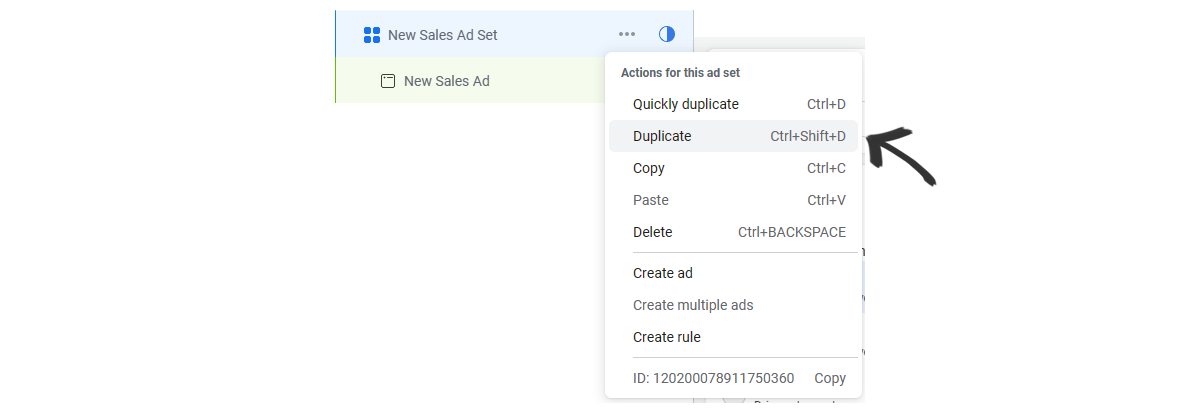
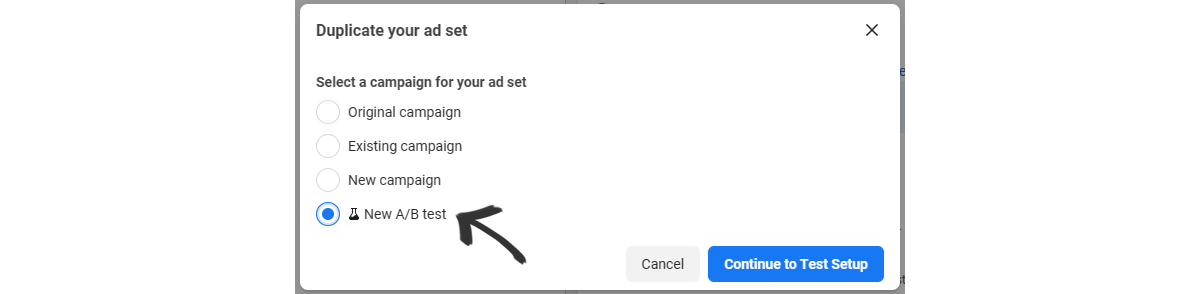
Once you do, a pop up will show up and you can select where the duplicate will go and you can then choose "New A/B test". After that, you can also set the settings for the test.
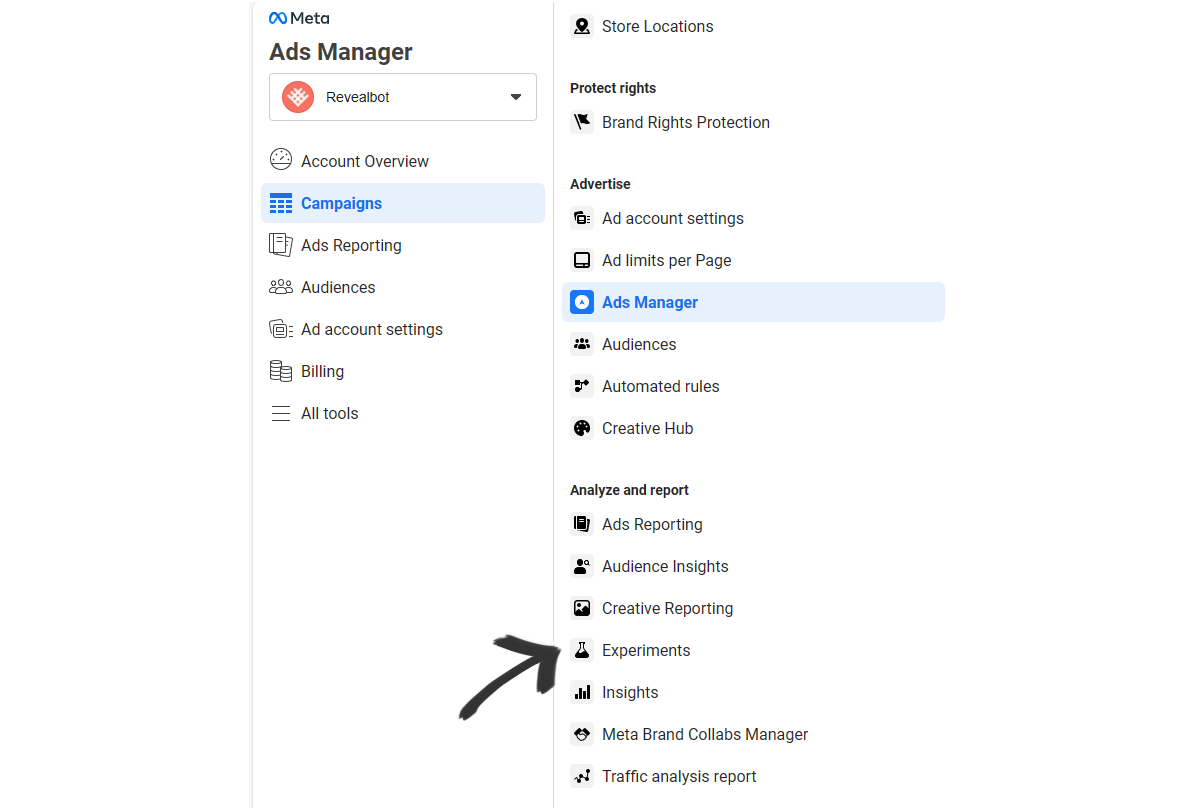
To go to the "Experiments" page, you will need to log in to your Ads Manager and from there, on the left column menu, choose "Experiments" under "Analyze and report".
Inside the page, click on "Get Started"
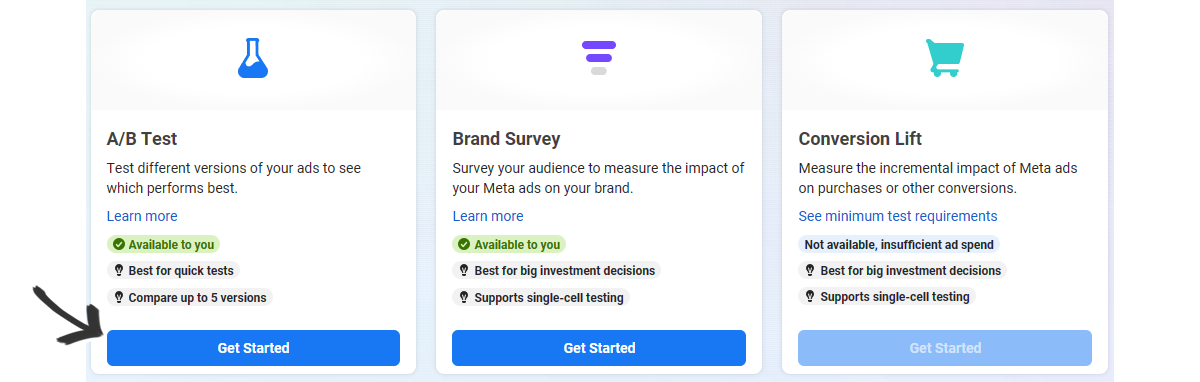
A pop up with the settings will come up and there you can choose the level which you want to test:
Then you will choose the campaigns or ad sets to test and, finally, up to 9 metrics to measure the results and choose the winners.
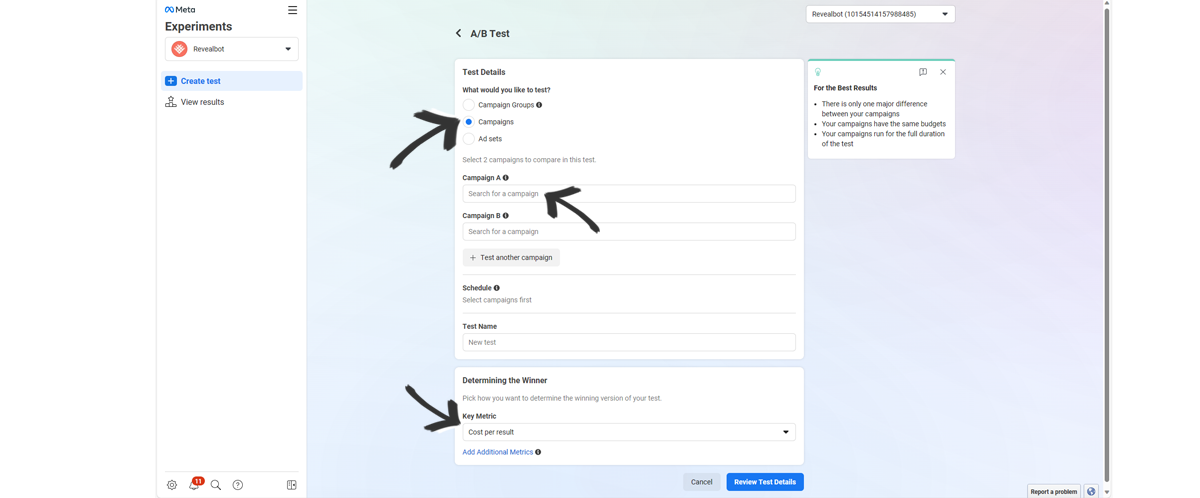
Even though the A/B tests from Facebook work, can you see how if you're testing many ad sets and campaigns at the same time, it can be a hassle?
That's why I prefer to use a more structured framework to split testing Facebook ads.
The ultimate goal of all tests is to improve a key metric. The first hard truth to accept is any test outcome is valuable as long as it answers the question, "should I roll out this change to the whole ad account?" even if that answer is "no." And this is why my initial approach failed. It didn’t give me any answers at all.
After courses on basic and inferential statistics, private classes with a university professor of statistics, and dozens of shipped Facebook A/B tests, I’ve learned many lessons about them. Here’s the exact approach and tools I use to setup and run tests that tell the truth.

1. Pick the metric to measure success
Calculate the baseline conversion. The closer to the top of the funnel, the smaller sample is needed.
2. Define success up-front
Estimate the minimum detectable effect.
3. Define the right sample size
Use a sample calculator. Set statistical power to 80% and significance level to 5%.
4. Define the budget
Multiply sample size by the cost per unique outbound click.
5. Define the period
Usually 2+ weeks. Based on the share of monthly budget you can allocate to the test.
6. Split your sample groups equally and randomly
Set up two rules in Revealbot that will randomly split ad sets into test and control groups.
7. Describe the test
Write down how you’ll manage the test group. Preferably set it up in the rules.
8. Monitor equal reach between test and control groups
Shares may skew over time. Keep the reach in both groups equal.

My main KPI has always been CPA (cost per acquisition). All the brands that I’ve worked with have always been very outcome-driven. Testing any proxy metric, such as CPC or CTR didn’t make much sense, because decrease in CPC does not necessarily lead to decrease in CPA.
I would define the baseline conversion as Purchases divided by Unique outbound clicks, the latter represents the number of people.
Another important step is the minimum detectable effect—the change in the metric you want to observe. This will tell you the sample size you need. The smaller the effect the more people you need to reach.
For example, if the CPA is $50, it means the conversion rate is 1.84%. I want to detect a decrease in CPA to $40, which equals increase in conversion to 2.30%. The minimum detectable effect would be 0.46%, 2.30% minus 1.84%

A question always arises when analyzing test results, "is the observed lift in conversion a result of the change that I made or random?"
Linking the uplift in conversion to the tested change when in reality it is not is related the false positive. To reduce the chance of reaching a false positive, we can calculate the statistical significance, which is a measurement of the level of confidence that a result is not likely due to chance. If we accept that there is a 5% chance the test results are wrong (accepted false positive rate), the statistical significance, therefore, is 100% minus 5%, or 95%. The higher the statistical significance the better as that means you can be more confident in your test’s results and 95% is the recommended level of significance you should strive for.
The other type of error that may occur in a test is called a false negative. It refers to the probability of reaching a negative result when in fact the test should have been positive. To reduce the chance of reaching a false negative, statisticians measure the statistical power, which is the probability that a test will correctly reach a negative result. The power is equal to 100% minus the false negative rate. It is generally accepted that the power of an A/B test should be at least 80%.
The minimum detectable effect, power, and statistical significance define the sample for your test. Thanks to the power of the Internet there is no need to do it by hand anymore. There’re many free calculators out there but I’m using this one.
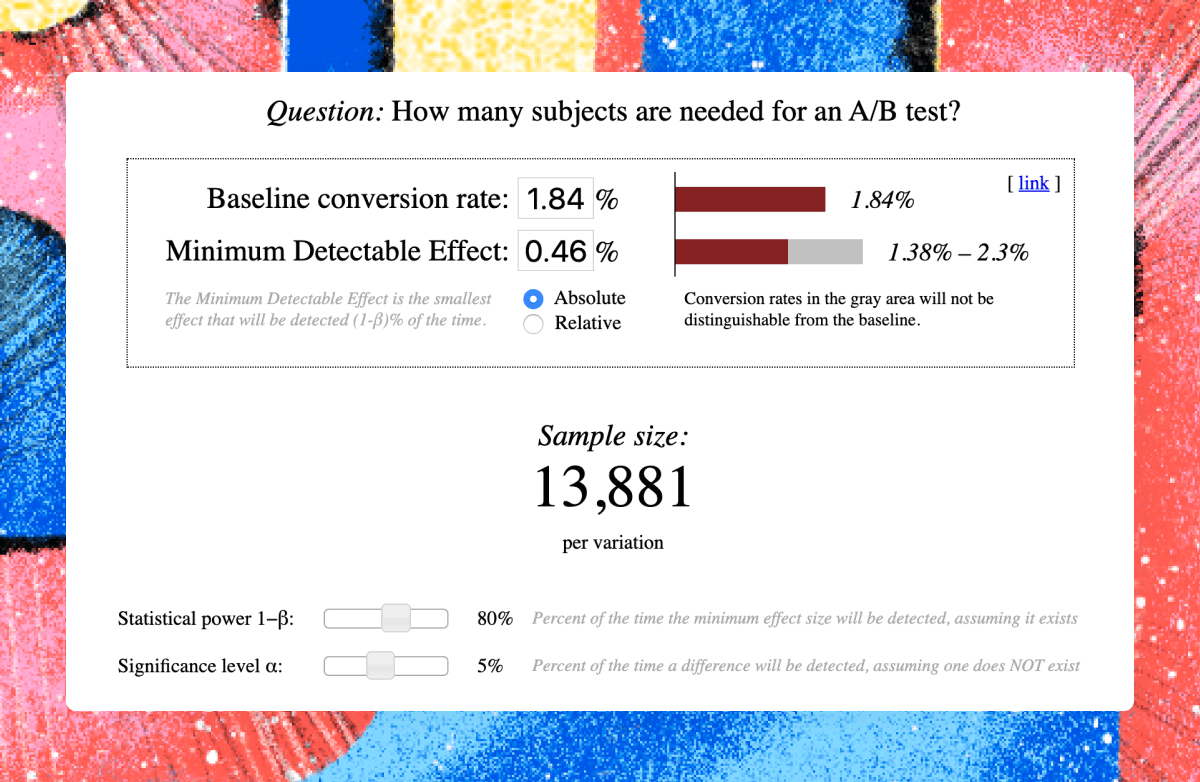
To detect the desired effect I’ll need 13,881 people in each variation, meaning 27,726 people in total.
Knowing the required sample size, you can estimate the budget for the test. My average cost per unique click is $0.92, so the budget will be 27,726 unique outbound clicks multiplied by $0.92, which equals $25,541.
A test usually runs for at least two weeks but can be active for several months. Both the control and test groups should be live at the same time so other factors don’t influence the test results.
Tests can be expensive and I like calculating the period based on the share of budget I can afford to allocate to the test.
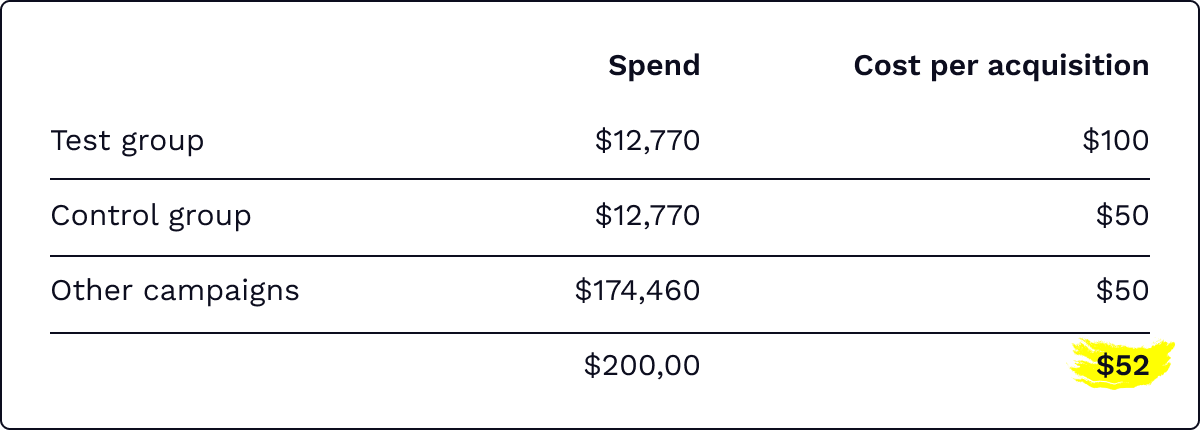
To do that, I consider the worst possible outcome—for example if the conversion rate drops by 50% in the test group. Let’s see what will happen with the total ad account's CPA in this case.
Let's assume my monthly ad spend is $200k and my target CPA is $50. If my test fails and conversion rate decreases to half its current value, my ad account’s total CPA will increase to $52. If this outcome is fine, then I don't need to run the test for more than two months. I could complete it within 2-4 weeks, but I’d prefer a longer period, so, in this case, four weeks.
That's a tricky one. There is no way to get two equal non-overlapping audiences in Ads Manager without the Split Test tool. The Split Test tool in the Ads Manager allows you to split an audience into several randomized groups, then test ad variations, placements, and some other variables. In my experience, these tests have always been much more expensive than I was ready to spend on them. They won’t let you test strategies as well, because you cannot make any changes to the test after it has been set live.
Knowing that Facebook's split tests don’t work for me, I found a workaround. I can just randomly assign ad sets to either the test or control groups. I decided to ignore that someone might belong to the test and control groups at the same time if the sample is big enough.
I might add my own bias if I choose to group the ad sets myself into either the control or test groups, so instead I can let a program do it. I used Revealbot's Facebook ad automation tool to assign one-half of ad sets to a test group and the other to the control group. Here's how I did it:
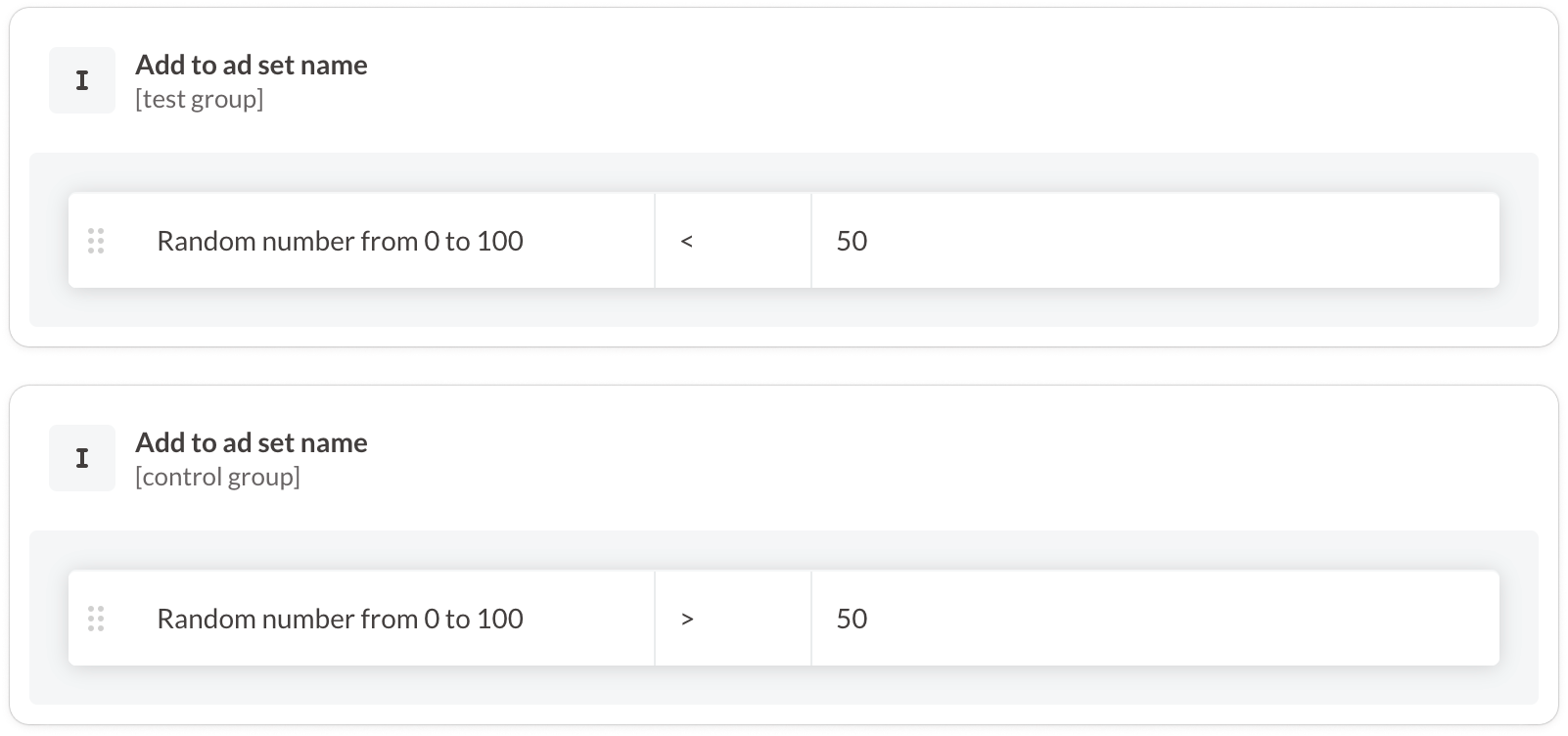
Problem solved.
But before splitting ad sets to the test and control groups, let's create one more rule that will limit the number of ad sets in the test. In the previous steps, I've estimated the total test budget to be $25,541, which is 13% of the total monthly budget ($200,000).
The following rule will assign 13% of all new ad sets to the test.
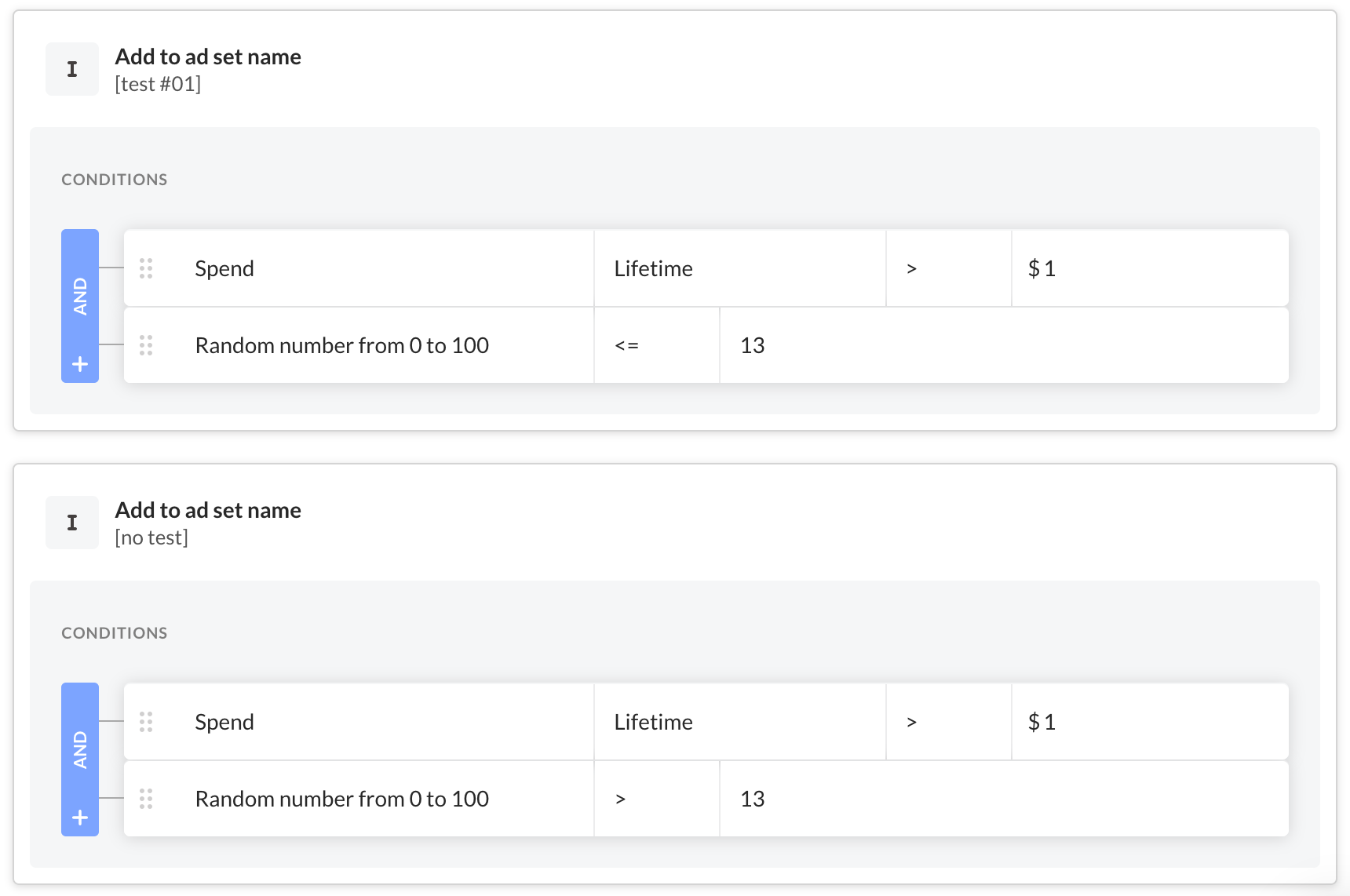
Follow this link to add this Revealbot Strategy to your account. If you don’t have Revealbot, you can get a free trial, or you’ll just have to pick the ad sets yourself and try your best to do it randomly to keep the test pure.
Determine how you’ll manage the test group. It should be a clear instruction that covers all scenarios. This is how a description could look like:
Ad sets on automatic bidding that have grown to a $2,000+ daily budget quickly drop the ad account's performance if their conversion rate goes below 20% of the target value. Lower conversion always results in higher CPA. If I observe high CPA for three consecutive days, I substitute the ad set with a new one with an identical audience. While the new ad set has a significantly lower daily budget, the purchase volume on the ad account decreases.
If I decrease the budget to $1,000 a day, the ad set will restore the target conversion rate and the ad account purchase volume will decrease less.
1. If an ad set's daily budget is greater than $2,000 and its conversion rate over the past three days including today is .8 of the target value, add "[downscale test]" to the ad set's name.
2. If an ad set has "[downscale test]" in the name, add "[test group] " to its name with a 50% probability.
3. If an ad set has "[downscale test]" and "[test group]" in the name, set its budget to $1,000 daily.
4. Check the conversion rate for each ad set five days after the downscale.
Preferably setup the test in automated rules.
Check the reach of the test and control groups regularly. Ad spend is volatile and may cause unequal budget allocation and therefore unequal reach to each group of the test. If this happens, even them out by changing how each group tag is assigned.
It seems like a lot of heavy lifting, but it’s just in the setup. Tests require time and budget. This is why it’s important to prioritize what you want to test first and define which hypothesis could drive the biggest impact. To reduce the cost, try detecting a bigger effect but never sacrifice power or significance for the sake of the cost of the test.
Have you done tests before and if so, how did they turn out?
To test Facebook ads can be a challenge, but it's worth it. It's the best way to find out what works and what doesn't for your ads.
I've learned a few things over the years, and I'm here to share them with you.
First, don't be afraid to experiment. Every test, even if it fails, teaches you something.
Second, focus on your KPIs. What are you trying to achieve with your ads? Once you know your KPIs, you can design tests that will help you reach your goals.
Third, be patient. It takes time to get meaningful results from A/B testing. Don't expect to see a big difference overnight.
Here are a few tips to help you get started:
A/B testing can be a lot of work, but it's worth it in the long run. By following these tips, you can improve your Facebook ads and get better results.
Happy testing!
A/B testing is a method of scientific experimentation that compares two versions of a variable to see which one performs better. In the context of Facebook advertising, A/B testing can be used to compare different ad images, ad text, audiences, placements, and other variables.
A/B testing is the best way to find out what works and what doesn't for your Facebook ads. It can help you improve your click-through rate (CTR), conversion rate (CVR), and other important metrics.
To create an A/B test on Facebook, you can use the split testing feature in Ads Manager. To do this, create a duplicate of your ad campaign, ad set, or ad. Then, make one change to the duplicate version. For example, you could change the ad image, ad text, or audience.
Once you have created your two versions, you can start your test. Facebook will randomly show each version to a different portion of your target audience. You can then monitor the results of your test to see which version performs better.
Another option is to use the "Experiments" page directly in the ads manager and test the different variations of the test.
You can test any variable that you think might impact the performance of your Facebook ads. Here are a few ideas:
The length of your test will depend on a few factors, such as your budget and the number of conversions you typically get.
However, it is generally recommended to run your test for at least 2 weeks.
First because there's the Facebook learning phase and it takes ate least a week for your ads to start delivering with the algorithm's optimizations. Second because it's the least amount of time to give you enough time to get statistically significant results.
Here are a few best practices for A/B testing on Facebook:

Masha is the Head of Product at Revealbot. Prior to joining the team, she was responsible for the growth at Function of Beauty, Blix, Scentbird, and Deck of Scarlet.


